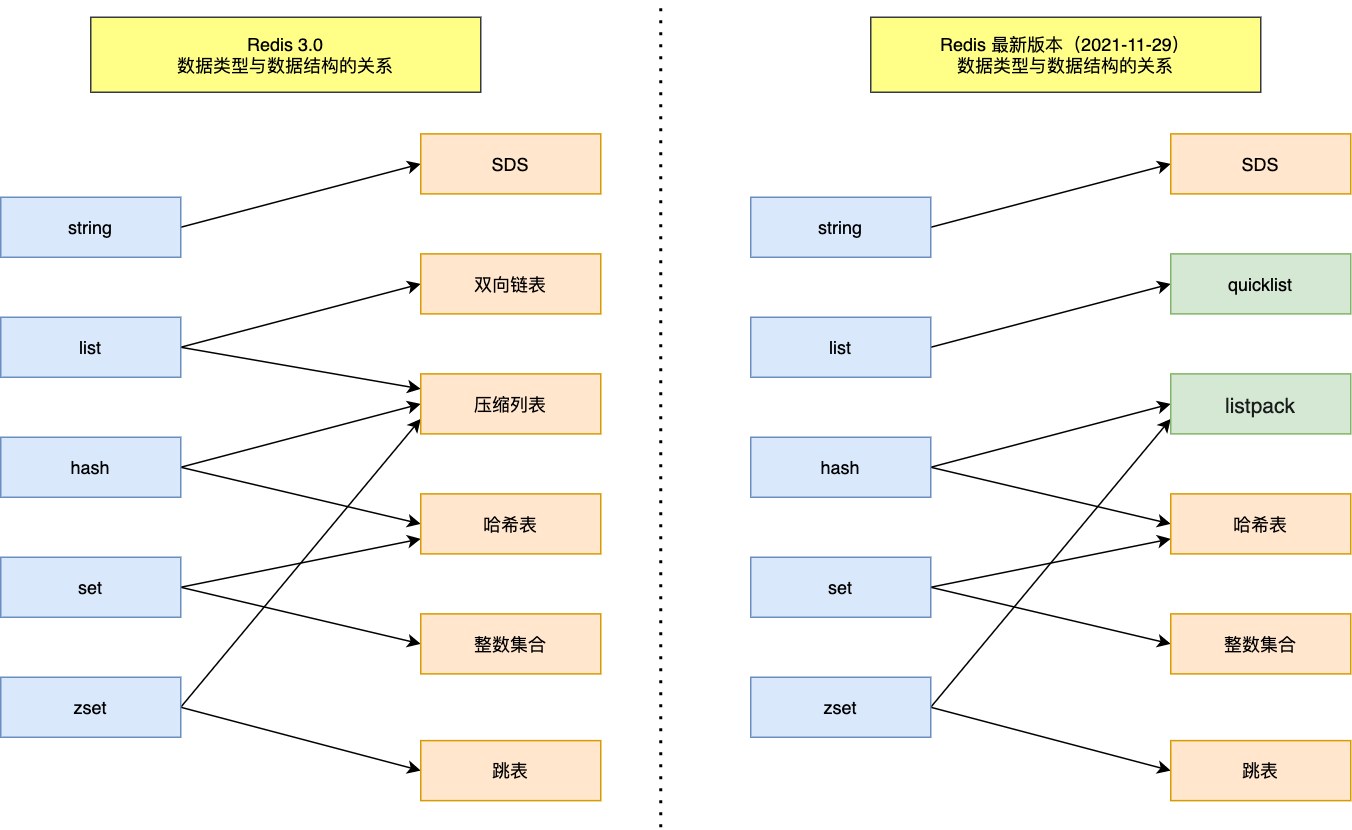
参考: Redis数据结构
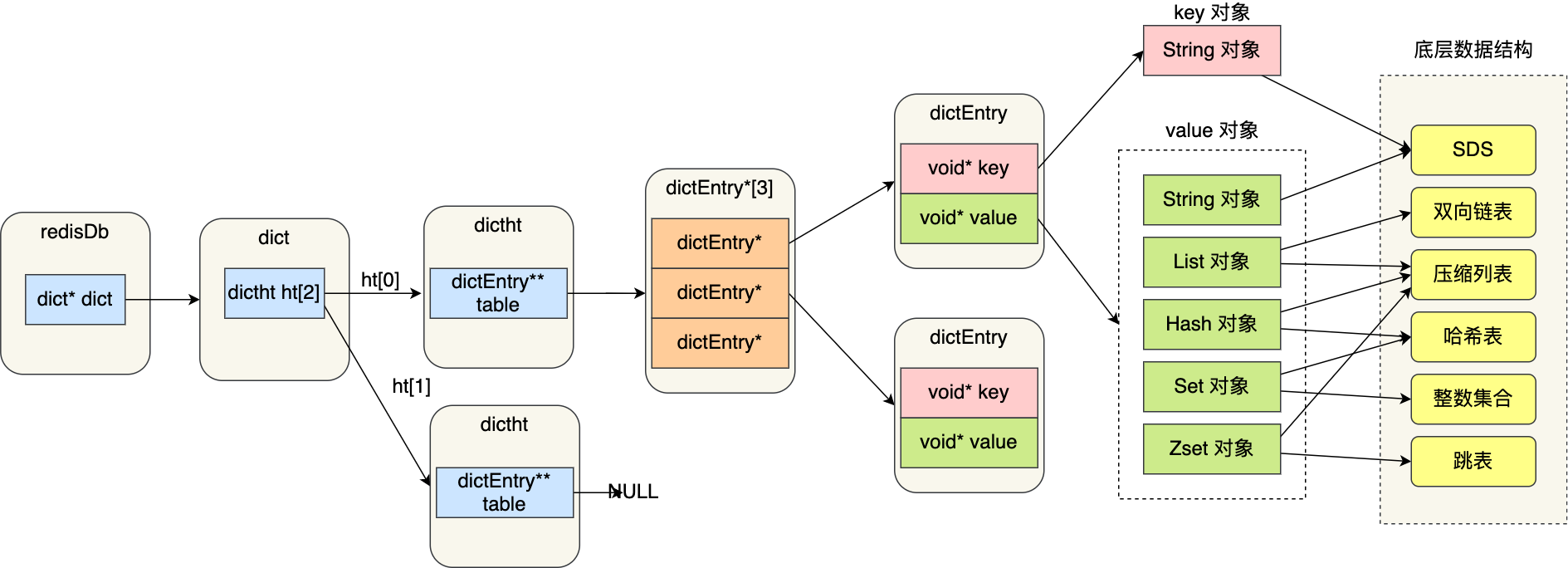
*redis存储访问流程
- redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向了 dict 结构的指针;
- dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用「哈希表1」,「哈希表2」只有在 rehash 的时候才用;
- ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
- dictEntry 结构,表示哈希表节点的结构,结构里存放了 void * key 和 void * value 指针, *key 指向的是 String 对象,而 *value 则可以指向 String 对象,也可以指向集合类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
string:字符串
redis使用c语言开发, 在redis中,其自己定义了一种字符串格式,叫做SDS(Simple Dynamic String),即简单动态字符串. 结构定义sds.h:
1 | typedef char *sds; |
sds包含以下属性:
- len:已使用的长度,即字符串的真实长度. 降低获取字符串长度复杂度到O(1). 同时帮助二进制安全
- alloc:分配的长度, 除去标头和终止符(‘\0’)后的长度. 减少而内存分配次数
- flags:表示不同类型的SDS, 低3位表示
- buf[]:存储字符数据
list:列表
使用双向链表, 获取节点前后节点时间复杂度O(1),获取头尾节点也是O(1). 同时链表使用指针保存值, 可以保存各种类型的数据.
1 | typedef struct list { |
ziplist
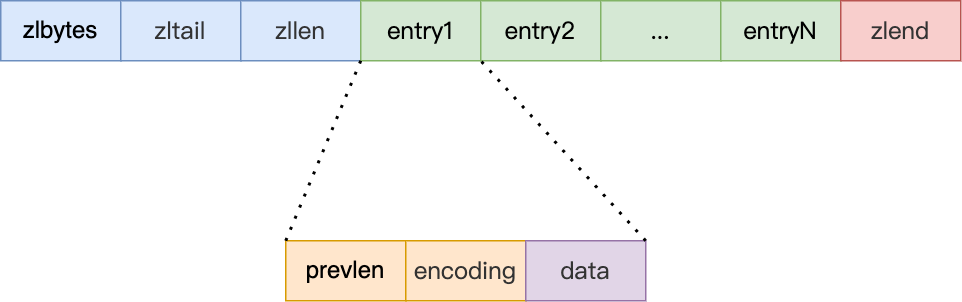
相比链表, 设计为更为内存紧凑的数据结构, 可以有效利用CPU缓存. 而且针对不同长度数据进行编码以节省内存开销. 同样存在缺陷: 不可以保存过多的元素,新增修改元素时,内存需要重分配和引发连锁更新问题.
- zlbytes:4个字节(32bits),表示ziplist占用的总字节数
- zltail:4个字节(32bits),表示ziplist中最后一个节点在ziplist中的偏移字节数
- entries:2个字节(16bits),表示ziplist中的元素数
- entry:长度不定,表示ziplist中的数据 (内部包含prevlen: 记录前一个节点长度(如果内存重新分配,后续的该字段都要更新,造成性能下降–连锁更新问题), encoding: 记录当前节点类型与长度, data: 数据)
- zlend:1个字节(8bits),表示结束标记,这个值固定为ff(255)
这些数据均为小端存储,所以可能有些人查看数据的二进制流与其含义对应不上,其实是因为读数据的方式错了
ziplist内部采取数据压缩的方式进行存储,压缩方式就不是重点了,我们仅从宏观来看,ziplist类似一个封装的数组,通过zltail可以方便地进行追加和删除尾部数据、使用entries可以方便地计算长度
但是其依然有数组的缺点,就是当插入和删除数据时会频繁地引起数据移动,所以就引出了quicklist数据类型
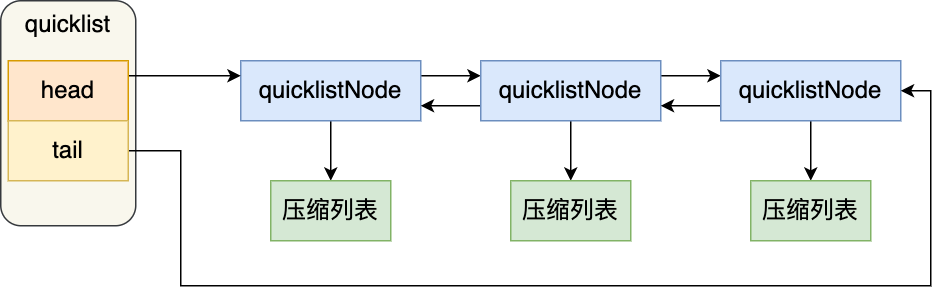
quick list
「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
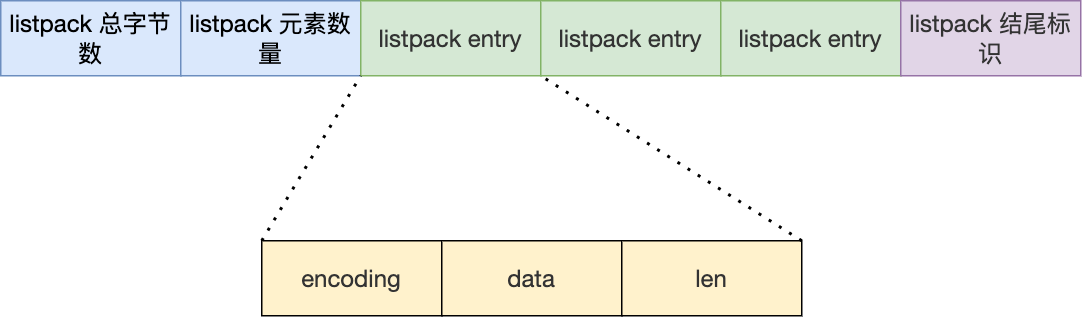
listpack
hash:散列表
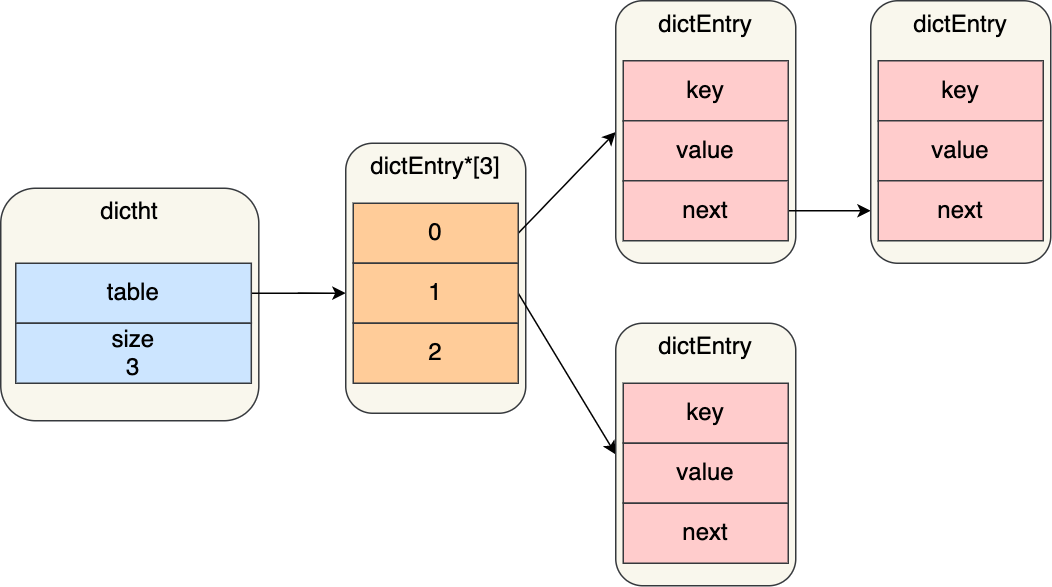
- 哈希冲突
- 链式哈希
- rehash
- 渐进式 rehash
- rehash 触发条件
set:无序集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。
- 整数集合
zset:有序集合
内部使用跳表
- 跳表
待补充